“Better code, better life. ”
Linux网络数据包接受过程
先来看一张图
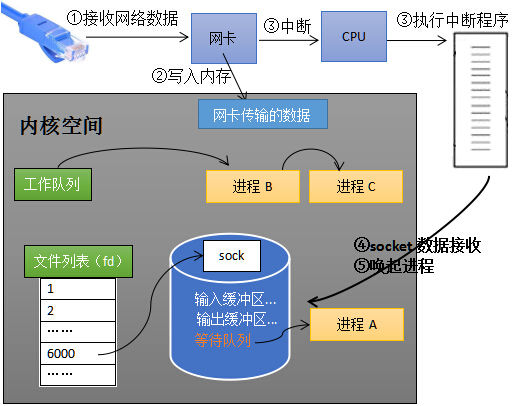
上面这张图描述了Linux内核在接受网络数据包的大概流程。
接收数据包是一个复杂的过程,涉及很多底层的技术细节,但大致需要以下几个步骤:
- 网卡收到数据包。
- 将数据包从网卡硬件缓存转移到服务器内存中。
- 通知内核处理。
- 经过TCP/IP协议逐层处理。
- 应用程序通过read()从socket buffer读取数据。
我们下面分步骤分别说明。
网卡接收数据包
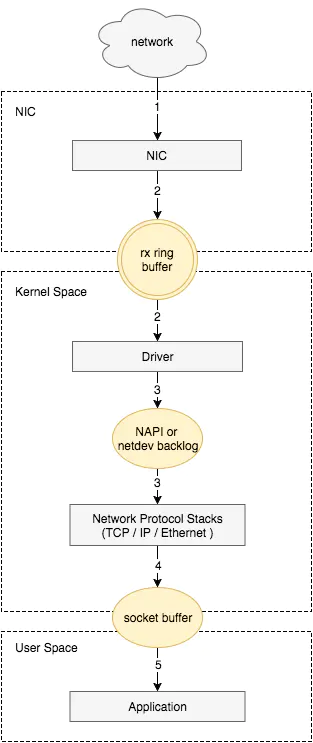
信息在链路层是以二进制传递的,也就是说网卡收到的数据包里只有一个个的高低电平所代表的二进制位。网卡将这些二进制位转换到网卡FIFO存储,然后再拷贝到系统主存(内存)中。其中涉及到网卡控制器,CPU,DMA,驱动程序,在OSI模型中属于物理层和链路层,如下图所示:
网卡工作在物理层和数据链路层,主要由PHY/MAC芯片、Tx/Rx FIFO、DMA等组成,其中网线通过变压器接PHY芯片、PHY芯片通过MII接MAC芯片、MAC芯片接PCI总线。
其中:
-
PHY芯片主要负责:CSMA/CD、模数转换、编解码、串并转换
- MAC芯片主要负责:比特流和帧的转换:7字节的前导码Preamble和1字节的帧首定界符SFD CRC校验
- Packet Filtering:L2 Filtering、VLAN Filtering、Manageability / Host Filtering
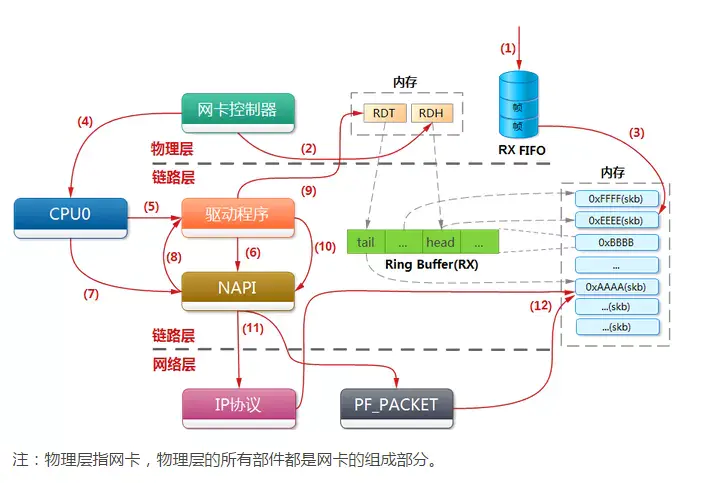
物理网卡收到数据包的处理流程如上图所示,详细步骤如下:
- 网卡收到数据包,先将高低电平转换到网卡fifo存储,网卡申请ring buffer的描述,根据描述找到具体的物理地址,从fifo队列物理网卡会使用DMA将数据包写到了该物理地址,,其实就是skb_buffer中.
- 这个时候数据包已经被转移到skb_buffer中,因为是DMA写入,内核并没有监控数据包写入情况,这时候NIC触发一个硬中断,每一个硬件中断会对应一个中断号,且指定一个vCPU来处理,如上图vcpu2收到了该硬件中断.
- 硬件中断的中断处理程序,调用驱动程序完成,a.启动软中断
- 硬中断触发的驱动程序会禁用网卡硬中断,其实这时候意思是告诉NIC,再来数据不用触发硬中断了,把数据DMA拷入系统内存即可
- 硬中断触发的驱动程序会启动软中断,启用软中断目的是将数据包后续处理流程交给软中断慢慢处理,这个时候退出硬件中断了,但是注意和网络有关的硬中断,要等到后续开启硬中断后,才有机会再次被触发
- NAPI触发软中断,触发napi系统
- 消耗ringbuffer指向的skb_buffer
- NAPI循环处理ringbuffer数据,处理完成
- 启动网络硬件中断,有数据来时候就可以继续触发硬件中断,继续通知CPU来消耗数据包.
其实上述过程过程简单描述为:网卡收到数据包,DMA到内核内存,中断通知内核数据有了,内核按轮次处理消耗数据包,一轮处理完成后,开启硬中断。其核心就是网卡和内核其实是生产和消费模型,网卡生产,内核负责消费,生产者需要通知消费者消费;如果生产过快会产生丢包,如果消费过慢也会产生问题。也就说在高流量压力情况下,只有生产消费优化后,消费能力够快,此生产消费关系才可以正常维持,所以如果物理接口有丢包计数时候,未必是网卡存在问题,也可能是内核消费的太慢。
网卡数据到内存
NIC在接收到数据包之后,首先需要将数据同步到内核中,这中间的桥梁是rx ring buffer。它是由NIC和驱动程序共享的一片区域,事实上,rx ring buffer存储的并不是实际的packet数据,而是一个描述符,这个描述符指向了它真正的存储地址,具体流程如下:
- 驱动在内存中分配一片缓冲区用来接收数据包,叫做sk_buffer;
- 将上述缓冲区的地址和大小(即接收描述符),加入到rx ring buffer。描述符中的缓冲区地址是DMA使用的物理地址;
- 驱动通知网卡有一个新的描述符;
- 网卡从rx ring buffer中取出描述符,从而获知缓冲区的地址和大小;
- 网卡收到新的数据包;
- 网卡将新数据包通过DMA直接写到sk_buffer中。
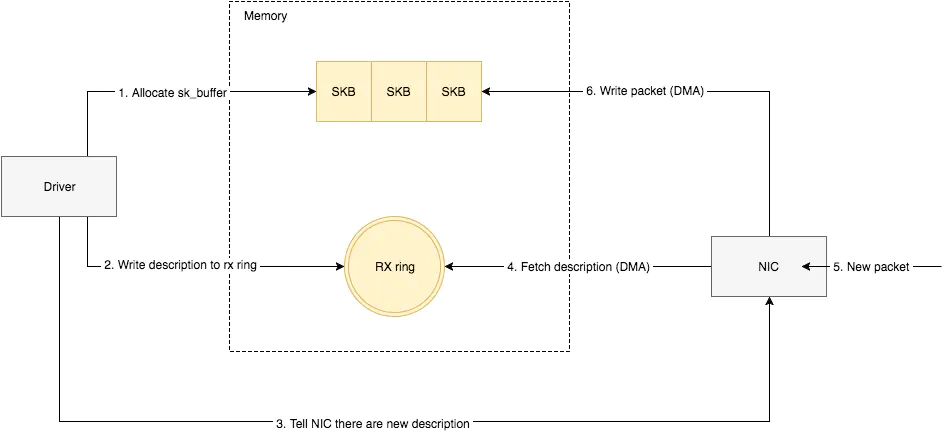
当驱动处理速度跟不上网卡收包速度时,驱动来不及分配缓冲区,NIC接收到的数据包无法及时写到sk_buffer,就会产生堆积,当NIC内部缓冲区写满后,就会丢弃部分数据,引起丢包。这部分丢包为rx_fifo_errors,在 /proc/net/dev中体现为fifo字段增长,在ifconfig中体现为overruns指标增长。
通知内核处理数据
这个时候,数据包已经被转移到了sk_buffer中。前文提到,这是驱动程序在内存中分配的一片缓冲区,并且是通过DMA写入的,这种方式不依赖CPU直接将数据写到了内存中,意味着对内核来说,其实并不知道已经有新数据到了内存中。那么如何让内核知道有新数据进来了呢?答案就是中断,通过中断告诉内核有新数据进来了,并需要进行后续处理。
提到中断,就涉及到硬中断和软中断,首先需要简单了解一下它们的区别:
- 硬中断: 由硬件自己生成,具有随机性,硬中断被CPU接收后,触发执行中断处理程序。中断处理程序只会处理关键性的、短时间内可以处理完的工作,剩余耗时较长工作,会放到中断之后,由软中断来完成。硬中断也被称为上半部分。
- 软中断: 由硬中断对应的中断处理程序生成,往往是预先在代码里实现好的,不具有随机性。(除此之外,也有应用程序触发的软中断,与本文讨论的网卡收包无关。)也被称为下半部分。
当NIC把数据包通过DMA复制到内核缓冲区sk_buffer后,NIC立即发起一个硬件中断。CPU接收后,首先进入上半部分,网卡中断对应的中断处理程序是网卡驱动程序的一部分,之后由它发起软中断,进入下半部分,开始消费sk_buffer中的数据,交给内核协议栈处理。
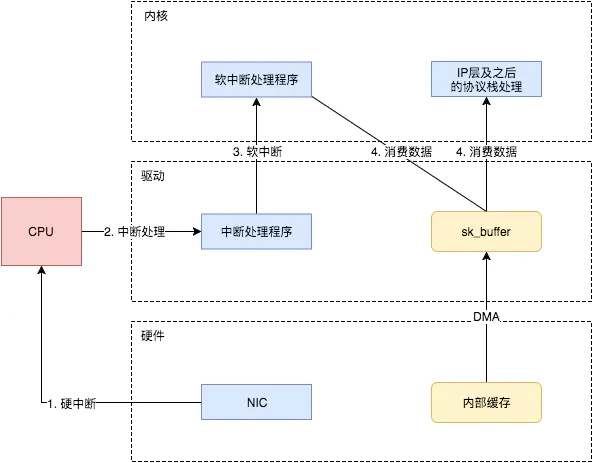
通过中断,能够快速及时地响应网卡数据请求,但如果数据量大,那么会产生大量中断请求,CPU大部分时间都忙于处理中断,效率很低。为了解决这个问题,现在的内核及驱动都采用一种叫NAPI(new API)的方式进行数据处理,其原理可以简单理解为 中断+轮询,在数据量大时,一次中断后通过轮询接收一定数量包再返回,避免产生多次中断。
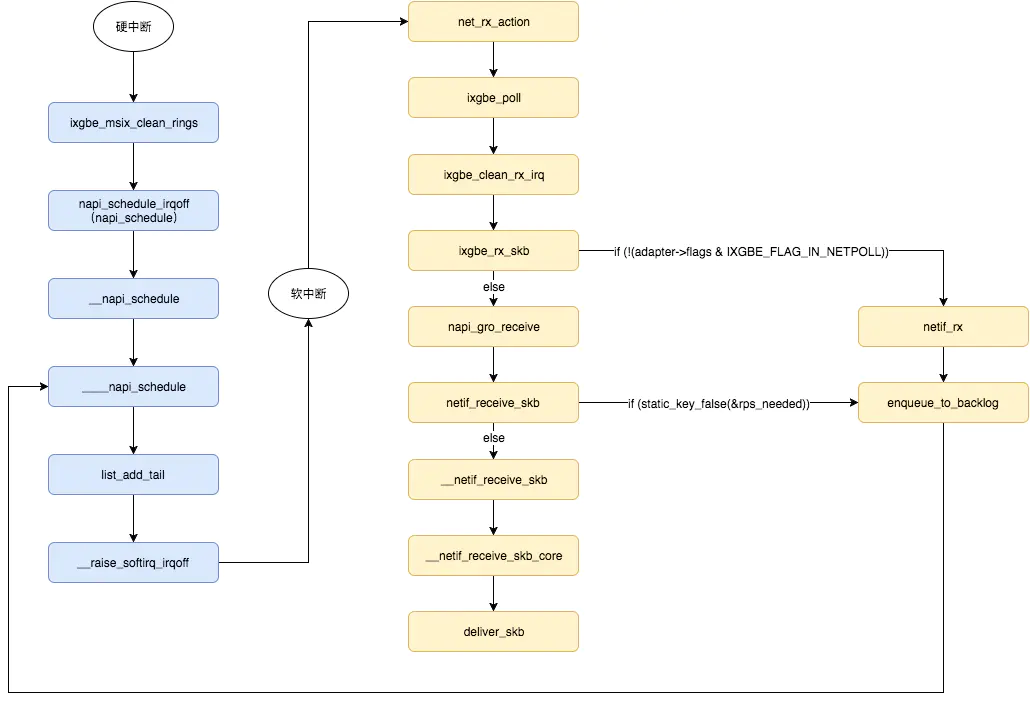
内核的网络模块
软中断会触发内核网络模块中的软中断处理函数,后续流程如下:
+-----+
17 | |
+----------->| NIC |
| | |
|Enable IRQ +-----+
|
|
+------------+ Memroy
| | Read +--------+--------+--------+--------+
+--------------->| NIC Driver |<--------------------- | Packet | Packet | Packet | ...... |
| | | 9 +--------+--------+--------+--------+
| +------------+
| | | skb
Poll | 8 Raise softIRQ | 6 +-----------------+
| | 10 |
| ↓ ↓
+---------------+ Call +-----------+ +------------------+ +--------------------+ 12 +---------------------+
| net_rx_action |<-------| ksoftirqd | | napi_gro_receive |------->| enqueue_to_backlog |----->| CPU input_pkt_queue |
+---------------+ 7 +-----------+ +------------------+ 11 +--------------------+ +---------------------+
| | 13
14 | + - - - - - - - - - - - - - - - - - - - - - - +
↓ ↓
+--------------------------+ 15 +------------------------+
| __netif_receive_skb_core |----------->| packet taps(AF_PACKET) |
+--------------------------+ +------------------------+
|
| 16
↓
+-----------------+
| protocol layers |
+-----------------+