“Better code, better life. ”
MYSQL如何保证事务的ACID特性
本篇文章源于之前的一场面试,面试官问了这个问题:
MYSQL如何保证事务的原子性?当时只回答了WAL(Write Ahead Log)机制,但其中的一些细节就不甚了解了,所以这次要彻底搞明白。
事务的特性
什么是事务?事务是指作为单个逻辑工作单元执行的一系列操作,这些操作要么全做,要么全不做,是一个不可分割的工作单元。
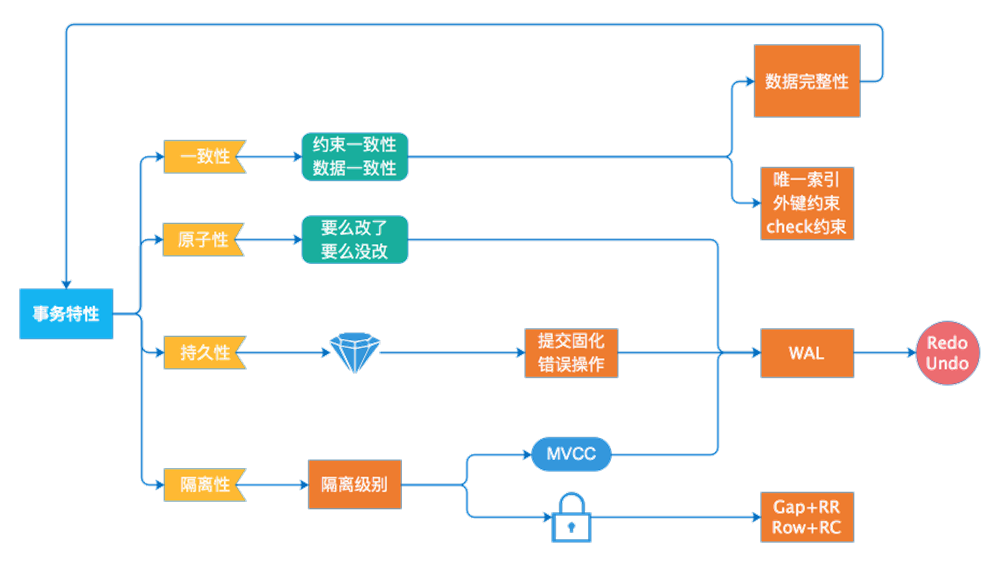
一个逻辑工作单元要成为事务,在关系型数据库管理系统中,必须满足 4 个特性,即所谓的 ACID:原子性、一致性、隔离性和持久性。
- 一致性:事务开始之前和事务结束之后,数据库的完整性限制未被破坏。
- 原子性:事务的所有操作,要么全部完成,要么全部不完成,不会结束在某个中间环节。
- 持久性:事务完成之后,事务所做的修改进行持久化保存,不会丢失。
- 隔离性:当多个事务并发访问数据库中的同一数据时,所表现出来的相互关系。
ACID 及它们之间的关系如下图所示,比如 4 个特性中有 3 个与 WAL 有关系,都需要通过 Redo、Undo 日志来保证等。
一致性
首先来看一致性,一致性其实包括两部分内容,分别是约束一致性和数据一致性。
约束一致性:大家应该很容易想到数据库中创建表结构时所指定的外键、Check、唯一索引等约束。可惜在 MySQL 中,是不支持 Check 的,只支持另外两种,所以约束一致性就非常容易理解了。
数据一致性:是一个综合性的规定,或者说是一个把握全局的规定。因为它是由原子性、持久性、隔离性共同保证的结果,而不是单单依赖于某一种技术。
原子性
接下来看原子性,原子性就是前面提到的两个“要么”,即要么改了,要么没改。也就是说用户感受不到一个正在改的状态。MySQL 是通过 WAL技术来实现这种效果的。
可能你想问,原子性和 WAL 到底有什么关系呢?其实关系非常大。举例来讲,如果事务提交了,那改了的数据就生效了,如果此时 Buffer Pool 的脏页没有刷盘,如何来保证改了的数据生效呢?就需要使用 Redo 日志恢复出来的数据。而如果事务没有提交,且 Buffer Pool 的脏页被刷盘了,那这个本不应该存在的数据如何消失呢?就需要通过 Undo 来实现了,Undo 又是通过 Redo 来保证的,所以最终原子性的保证还是靠 Redo 的 WAL 机制实现的。
持久性
再来看持久性。所谓持久性,就是指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的,接下来的操作或故障不应该对其有任何影响。前面已经讲到,事务的原子性可以保证一个事务要么全执行,要么全不执行的特性,这可以从逻辑上保证用户看不到中间的状态。但持久性是如何保证的呢?一旦事务提交,通过原子性,即便是遇到宕机,也可以从逻辑上将数据找回来后再次写入物理存储空间,这样就从逻辑和物理两个方面保证了数据不会丢失,即保证了数据库的持久性。
隔离性
最后看下隔离性。所谓隔离性,指的是一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对其他的并发事务是隔离的。锁和多版本控制就符合隔离性。
并发事务的控制
单版本控制-锁
先来看锁,锁用独占的方式来保证在只有一个版本的情况下事务之间相互隔离,所以锁可以理解为单版本控制。
在 MySQL 事务中,锁的实现与隔离级别有关系,在 RR(Repeatable Read)隔离级别下,MySQL 为了解决幻读的问题,以牺牲并行度为代价,通过 Gap 锁来防止数据的写入,而这种锁,因为其并行度不够,冲突很多,经常会引起死锁。现在流行的 Row 模式可以避免很多冲突甚至死锁问题,所以推荐默认使用 Row + RC(Read Committed)模式的隔离级别,可以很大程度上提高数据库的读写并行度。
多版本控制-MVCC
多版本控制也叫作 MVCC,是指在数据库中,为了实现高并发的数据访问,对数据进行多版本处理,并通过事务的可见性来保证事务能看到自己应该看到的数据版本。
那个多版本是如何生成的呢?每一次对数据库的修改,都会在 Undo 日志中记录当前修改记录的事务号及修改前数据状态的存储地址(即 ROLL_PTR),以便在必要的时候可以回滚到老的数据版本。例如,一个读事务查询到当前记录,而最新的事务还未提交,根据原子性,读事务看不到最新数据,但可以去回滚段中找到老版本的数据,这样就生成了多个版本。
多版本控制很巧妙地将稀缺资源的独占互斥转换为并发,大大提高了数据库的吞吐量及读写性能。
了解了单版本控制(锁)和多版本控制(MVCC),相信你对数据库的设置及并发性已经有了比较深入的理解。
特性背后的技术原理
接下来看一下每个特性是通过什么技术原理实现的。
原子性背后的技术
先来看看原子性,每一个写事务,都会修改 Buffer Pool,从而产生相应的 Redo 日志,这些日志信息会被记录到 ib_logfiles 文件中。因为 Redo 日志是遵循 Write Ahead Log 的方式写的,所以事务是顺序被记录的。
在 MySQL 中,任何 Buffer Pool 中的页被刷到磁盘之前,都会先写入到日志文件中,这样做有两方面的保证。
如果 Buffer Pool 中的这个页没有刷成功,此时数据库挂了,那在数据库再次启动之后,可以通过 Redo 日志将其恢复出来,以保证脏页写下去的数据不会丢失,所以必须要保证 Redo 先写。
因为 Buffer Pool 的空间是有限的,要载入新页时,需要从 LRU 链表中淘汰一些页,而这些页必须要刷盘之后,才可以重新使用,那这时的刷盘,就需要保证对应的 LSN 的日志也要提前写到 ib_logfiles 中,如果没有写的话,恰巧这个事务又没有提交,数据库挂了,在数据库启动之后,这个事务就没法回滚了。所以如果不写日志的话,这些数据对应的回滚日志可能就不存在,导致未提交的事务回滚不了,从而不能保证原子性,所以原子性就是通过 WAL 来保证的。
持久性背后的技术
再来看持久性,如下图所示,一个“提交”动作触发的操作有:binlog 落地、发送 binlog、存储引擎提交、flush_logs, check_point、事务提交标记等。这些都是数据库保证其数据完整性、持久性的手段。
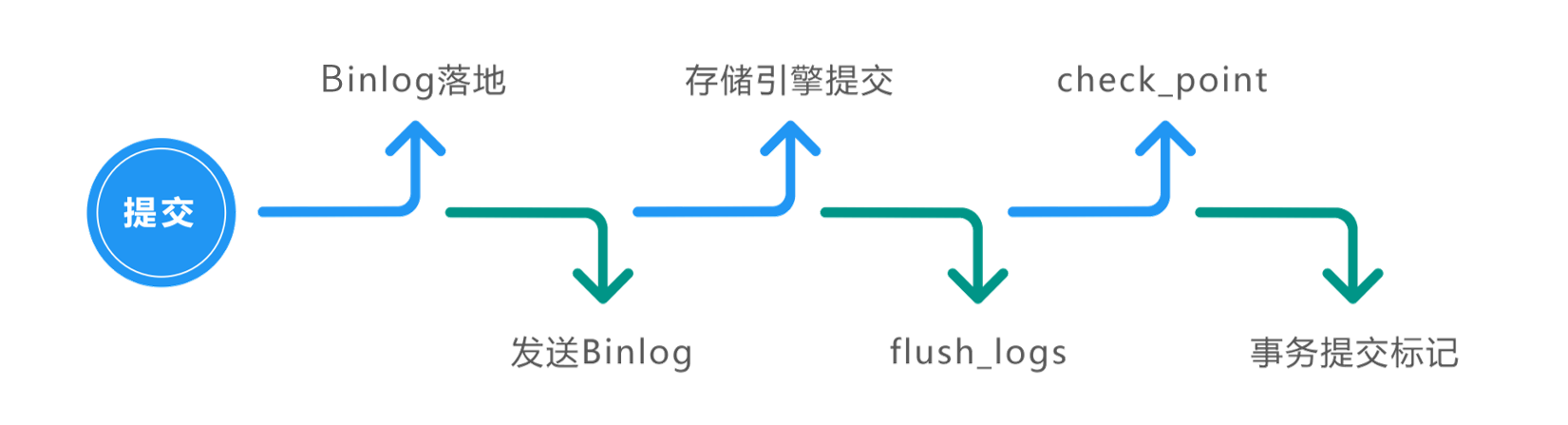
那这些操作如何做到持久性呢?前面讲过,通过原子性可以保证逻辑上的持久性,通过存储引擎的数据刷盘可以保证物理上的持久性。这个过程与前面提到的 Redo 日志、事务状态、数据库恢复、参数 innodb_flush_log_at_trx_commit 有关,还与 binlog 有关。这里多提一句,在数据库恢复时,如果发现某事务的状态为 Prepare,则会在 binlog 中找到对应的事务并将其在数据库中重新执行一遍,来保证数据库的持久性。
隔离性背后的技术
接下来看隔离性,InnoDB 支持的隔离性有 4 种,隔离性从低到高分别为:读未提交、读提交、可重复读、可串行化。
- 读未提交(RU,Read Uncommitted)。它能读到一个事务的中间过程,违背了 ACID 特性,存在脏读的问题,所以基本不会用到,可以忽略。
- 读提交(RC,Read Committed)。它表示如果其他事务已经提交,那么我们就可以看到,这也是一种最普遍适用的级别。但由于一些历史原因,可能 RC 在生产环境中用的并不多。
- 可重复读(RR,Repeatable Read),是目前被使用得最多的一种级别。其特点是有 Gap 锁、目前还是默认的级别、在这种级别下会经常发生死锁、低并发等问题。
- 可串行化,这种实现方式,其实已经并不是多版本了,又回到了单版本的状态,因为它所有的实现都是通过锁来实现的。
具体说到隔离性的实现方式,我们通常用 Read View 表示一个事务的可见性。前面讲到 RC 级别的事务可见性比较高,它可以看到已提交的事务的所有修改。而 RR 级别的事务,则没有这个功能,一个读事务中,不管其他事务对这些数据做了什么修改,以及是否提交,只要自己不提交,查询的数据结果就不会变。这是如何做到的呢?
随着时间的推移,读提交每一条读操作语句都会获取一次 Read View,每次更新之后,都会获取数据库中最新的事务提交状态,也就可以看到最新提交的事务了,即每条语句执行都会更新其可见性视图。而反观下面的可重复读,这个可见性视图,只有在自己当前事务提交之后,才去更新,所以与其他事务是没有关系的。
这里需要提醒大家的是:在 RR 级别下,长时间未提交的事务会影响数据库的 PURGE 操作,从而影响数据库的性能,所以可以对这样的事务添加一个监控。
最后我们来讲下可串行化的隔离级别,前面已经提到了,可串行化是通过锁来实现的,所以实际上并不是多版本控制,它的特点也很明显:读锁、单版本控制、并发低。
一致性背后的技术
接下来是一致性。一致性可以归纳为数据的完整性。根据前文可知,数据的完整性是通过其他三个特性来保证的,包括原子性、隔离性、持久性,而这三个特性,又是通过 Redo/Undo 来保证的,正所谓:合久必分,分久必合,三足鼎力,三分归晋,数据库也是,为了保证数据的完整性,提出来三个特性,这三个特性又是由同一个技术来实现的,所以理解 Redo/Undo 才能理解数据库的本质。
MVCC实现原理
前文多次提到了 MVCC 这个概念,这里我们来讲解 MVCC 的实现原理。MySQL InnoDB 存储引擎,实现的是基于多版本的并发控制协议——MVCC,而不是基于锁的并发控制。
MVCC 最大的好处是读不加锁,读写不冲突。在读多写少的 OLTP(On-Line Transaction Processing)应用中,读写不冲突是非常重要的,极大的提高了系统的并发性能,这也是为什么现阶段几乎所有的 RDBMS(Relational Database Management System),都支持 MVCC 的原因。
快照读与当前读
在 MVCC 并发控制中,读操作可以分为两类: 快照读(Snapshot Read)与当前读 (Current Read)。
- 快照读:读取的是记录的可见版本(有可能是历史版本),不用加锁。
- 当前读:读取的是记录的最新版本,并且当前读返回的记录,都会加锁,保证其他事务不会再并发修改这条记录。
注意:MVCC 只在 Read Commited 和 Repeatable Read 两种隔离级别下工作。
如何区分快照读和当前读呢? 可以简单的理解为:
-
快照读:简单的 select 操作,属于快照读,不需要加锁。
-
当前读:特殊的读操作,插入/更新/删除操作,属于当前读,需要加锁。
MVCC 多版本实现
为了更直观的说明 MVCC 的实现原理,这里举一个“事务对某行记录更新的过程”的案例来讲解 MVCC 中多版本的实现。
-
假设 F1~F6 是表中字段的名字,1~6 是其对应的数据。后面三个隐含字段分别对应该行的隐含ID、事务号和回滚指针,如下图所示。
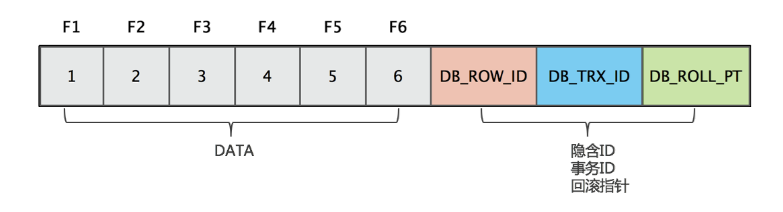
- 隐含 ID(DB_ROW_ID),6 个字节,当由 InnoDB 自动产生聚集索引时,聚集索引包括这个 DB_ROW_ID 的值。
- 事务号(DB_TRX_ID),6 个字节,标记了最新更新这条行记录的 Transaction ID,每处理一个事务,其值自动 +1。
- 回滚指针(DB_ROLL_PT),7 个字节,指向当前记录项的 Rollback Segment 的 Undo log记录,通过这个指针才能查找之前版本的数据。
具体的更新过程,简单描述如下。
- 首先,假如这条数据是刚 INSERT 的,可以认为 ID 为 1,其他两个字段为空。
- 然后,当事务 1 更改该行的数据值时,会进行如下操作:
- 用排他锁锁定该行;记录 Redo log;
- 把该行修改前的值复制到 Undo log;
- 修改当前行的值,填写事务编号,使回滚指针指向 Undo log 中修改前的行。
接下来,与事务 1 相同,此时 Undo log 中有两行记录,并且通过回滚指针连在一起。因此,如果 Undo log 一直不删除,则会通过当前记录的回滚指针回溯到该行创建时的初始内容,所幸的是在 InnoDB 中存在 purge 线程,它会查询那些比现在最老的活动事务还早的 Undo log,并删除它们,从而保证 Undo log 文件不会无限增长。